论文解析
MLP-Mixer: An all-MLP Architecture for Vision
作者单位:原ViT作者团队(Google Research)
代码:https://github.com/google-research/vision_transformer
论文:https://arxiv.org/abs/2105.0160
这篇论文是谷歌大脑的研究员(原ViT团队)在网络架构设计方面挖的新坑,它无需卷积、注意力机制,MLP-Mixer仅需MLP即可达到与CNN、Transformer相媲美的性能。 比如,在JFT-300M数据集预训练+ImageNet微调后,所提Mixer-H/14取得87.94%的top1精度。
我们先简单了解一下,MLP-Mixer这篇论文的创新点和不足:
MLP-Mixer无需卷积与自注意力。相反,MLP-Mixer仅仅依赖于在空域或者特征通道上重复实施的多层感知器 ,和基础的矩阵乘法操作 、数据尺度变换 (比如reshape、transposition)以及非线性层 。当在大数据集上训练,或者采用先进正则技术训练后,MLP-Mixer在图像分类基准数据集上取得了极具竞争力的性能。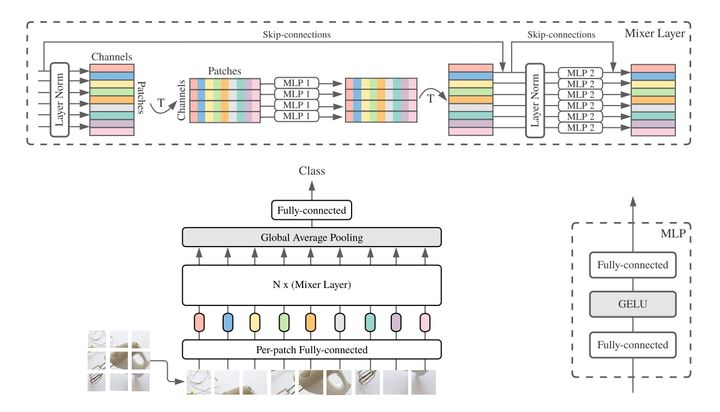 MLP-Mixer的网络结构如上图所示是MLP-Mixer的网络结构,它以一系列图像块的线性投影,其形状为(Patches x , Channels)缩写为(S, C)作为输入,其中C是输入数据的通道数,假设原始输入图像分辨率为![[公式]](https://www.zhihu.com/equation?tex=H+%5Ctimes+W),每个块的分辨率为![[公式]](https://www.zhihu.com/equation?tex=P%5Ctimes+P),就那么序列长度![[公式]](https://www.zhihu.com/equation?tex=S%3DHW%2FP%5E2)。
MLP-Mixer的网络结构如上图所示是MLP-Mixer的网络结构,它以一系列图像块的线性投影,其形状为(Patches x , Channels)缩写为(S, C)作为输入,其中C是输入数据的通道数,假设原始输入图像分辨率为![[公式]](https://www.zhihu.com/equation?tex=H+%5Ctimes+W),每个块的分辨率为![[公式]](https://www.zhihu.com/equation?tex=P%5Ctimes+P),就那么序列长度![[公式]](https://www.zhihu.com/equation?tex=S%3DHW%2FP%5E2)。
MLP-Mixer采用了两种类型的MLP层(注:这两种类型的MLP层交替出现,促进了两个维度间的信息交互):
- Channel-mixing MLP:允许不同通道之间进行通信,每个token独立处理,即采用每一行作为输入。
- token-mixingMLP:允许不同空间位置(token)之间进行通信,每个通道图例处理,即采用每一列作为输入。
重点是: 在极端情况下,MLP-Mixer所提架构可视作一种特殊CNN,它采用 ![[公式]](https://www.zhihu.com/equation?tex=1%5Ctimes1) 卷积进行channel mixing,全感受野、参数共享的的单通道深度卷积进行token mixing。
这篇论文也存在着一些不足:
- 结果毕竟没有达到SOTA,只能说可以比较,与ViT还是相差甚远。
- MLP-Mixer也加入了诸如残差结构,LayerNorm这些结构,这其实是最近CNN, Transformer发展的产物,除去这些,效果可能不尽人意。
- Mixer的扩展性没有Transformer强,Transformer的超强扩展性是它横扫CV, NLP等各大任务的原因。而Mixer并没有那么友好的Encoder-Decoder结构,扩展性就没有那么强了。
- Transformer是self attention(SA)和MLP结合的产物,个人觉得SA用于对特征进行选择(判断那些特征重要,那些不重要,关注重要的,忽略不重要的),MLP用于特征的增强。而Mixer虽然在spatial 和channel两个纬度对信息进行了增强,但由于缺少了特征选择的步骤,所以性能上差点意思。
实验及结果:
该研究用实验对 MLP-Mixer 模型的性能进行了评估。其中,模型在中大规模数据集上进行预训练,采用一系列中小型下游分类任务,并对以下三个问题进行重点研究:
- 在下游任务上的准确率;
- 预训练的总计算成本,这对于在上游数据集上从头开始训练模型非常重要;
- 推断时的吞吐量,这在实际应用中非常重要。
该研究的实验目的不是展示 SOTA 结果,而在于表明:一个简单的基于 MLP 的模型就可以取得与当前最佳的 CNN、基于注意力的模型相媲美的性能。
下表 1 列出了 Mixer 模型的各种配置以对标一些最新的 SOTA CNN 和基于注意力的模型: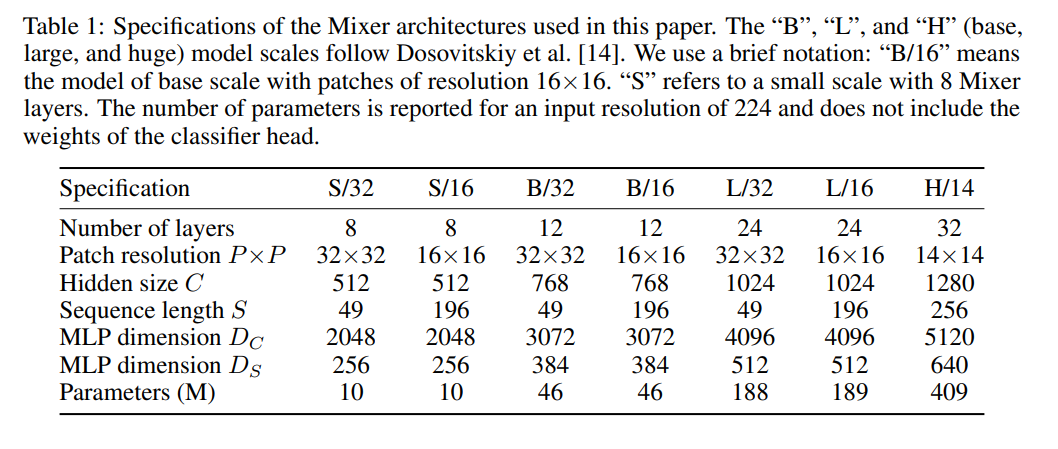 下表 2 给出了最大 Mixer 模型与 SOTA 模型的性能对比结果:
下表 2 给出了最大 Mixer 模型与 SOTA 模型的性能对比结果: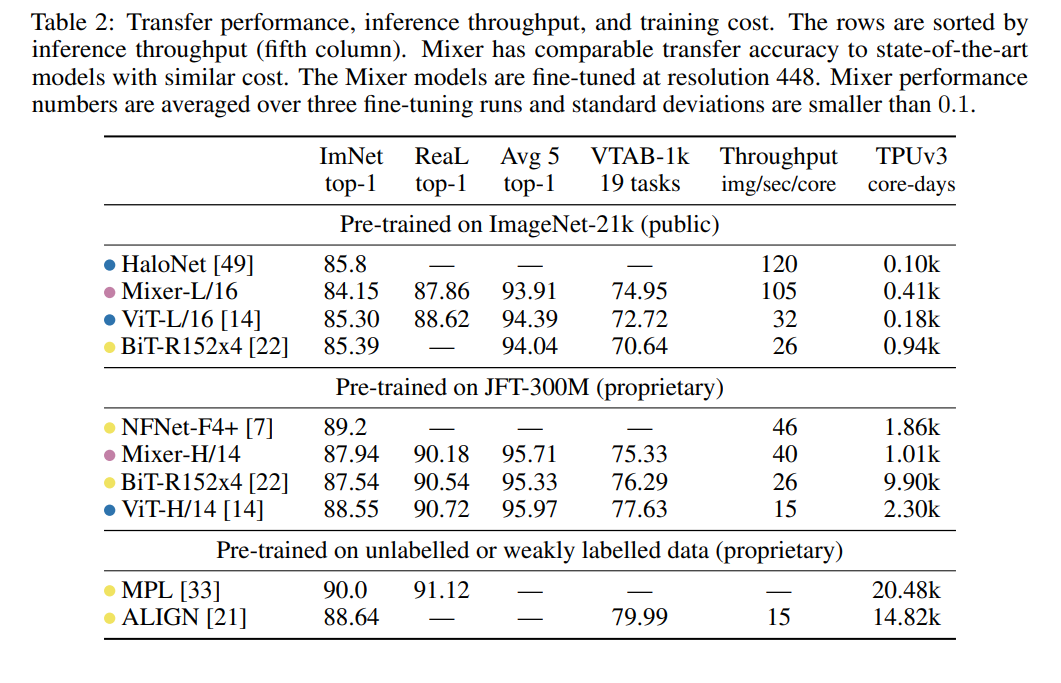 当在 ImageNet-21k 上进行带有额外正则化的预训练时,Mixer 实现了非常好的性能(ImageNet 上 84.15% top-1),略低于其他模型。当上游数据集的大小增加时,Mixer 的性能显著提高。具体来说,Mixer-H/14 在 ImageNet 上取得了 87.94% top-1 的准确率,比 BiT-ResNet152x4 高 0.5%,比 ViT-H/14 低 0.5%。值得一提的是,Mixer-H/14 的运行速度要比 ViT-H/14 快 2.5 倍,比 BiT 快 2 倍。
当在 ImageNet-21k 上进行带有额外正则化的预训练时,Mixer 实现了非常好的性能(ImageNet 上 84.15% top-1),略低于其他模型。当上游数据集的大小增加时,Mixer 的性能显著提高。具体来说,Mixer-H/14 在 ImageNet 上取得了 87.94% top-1 的准确率,比 BiT-ResNet152x4 高 0.5%,比 ViT-H/14 低 0.5%。值得一提的是,Mixer-H/14 的运行速度要比 ViT-H/14 快 2.5 倍,比 BiT 快 2 倍。
图 2(左)展示了表 2 中 SOTA 模型在 ImageNet 数据集上的准确率、训练成本帕累托前沿(Pareto frontier):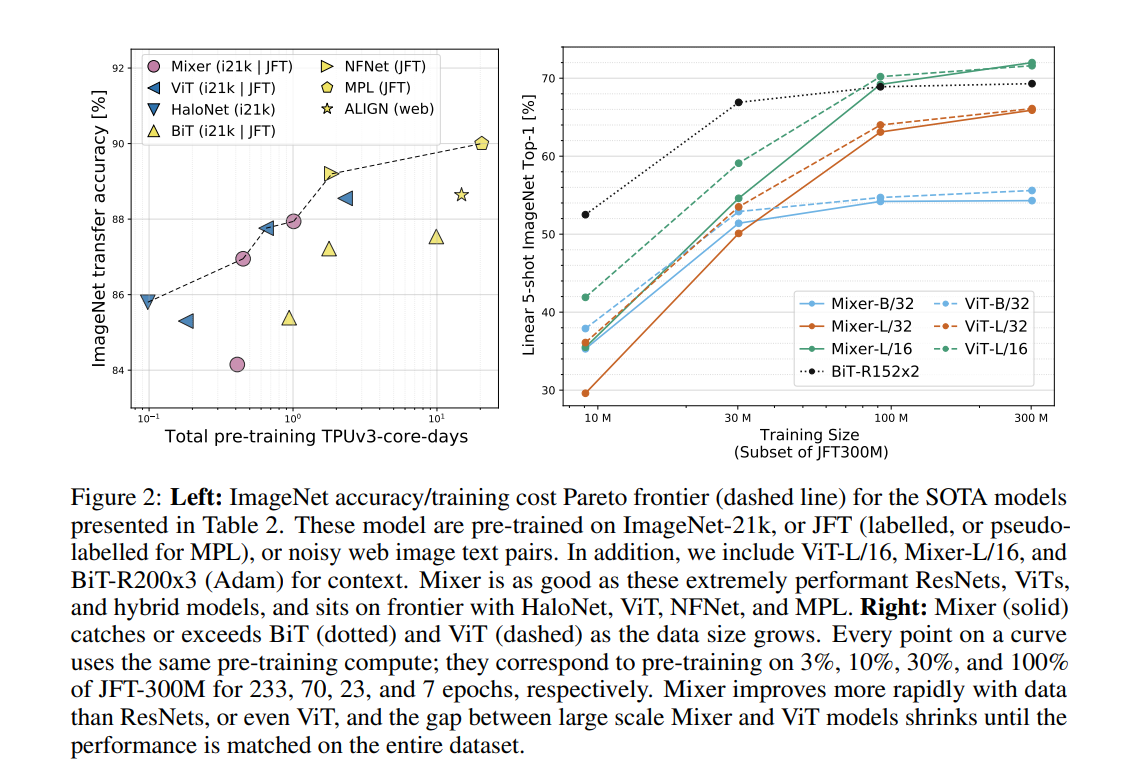 下表展示了在多种模型和预训练是数据集规模上,Mixer 和其他一些模型的性能对比结果:
下表展示了在多种模型和预训练是数据集规模上,Mixer 和其他一些模型的性能对比结果: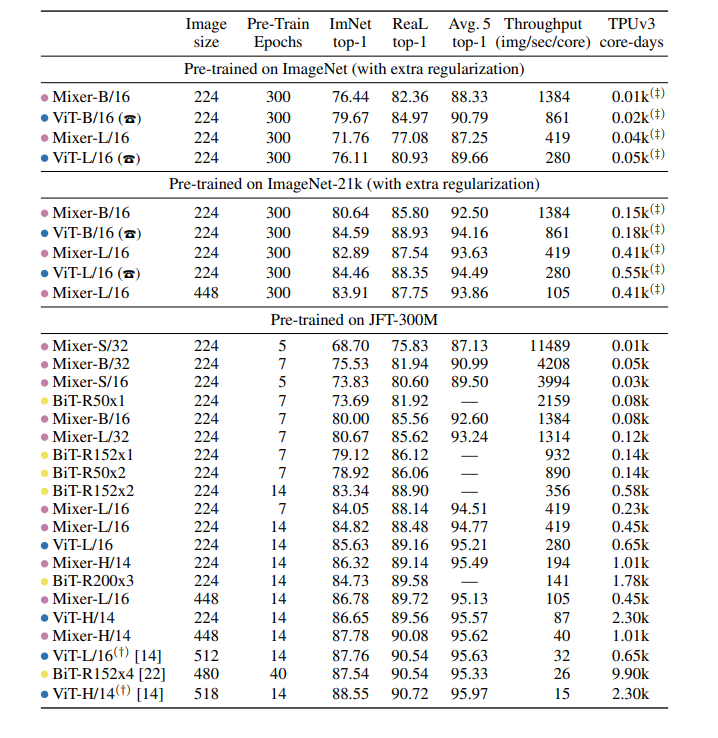 由上表可得,当在 ImageNet 上从头开始训练时, Mixer-B/16 取得了一个合理的 top-1 准确率 76.44%,这要比 ViT-B/16 低 3%。随着预训练数据集的增大,Mixer 的性能逐步提升。值得一提的是,在 JFT-300M 数据集上预训练、微调到 224 分辨率的 Mixer-H/14 取得了 86.32% 的准确率,比 ViT-H/14 仅低 0.3%,但运行速度是其 2.2 倍。
由上表可得,当在 ImageNet 上从头开始训练时, Mixer-B/16 取得了一个合理的 top-1 准确率 76.44%,这要比 ViT-B/16 低 3%。随着预训练数据集的增大,Mixer 的性能逐步提升。值得一提的是,在 JFT-300M 数据集上预训练、微调到 224 分辨率的 Mixer-H/14 取得了 86.32% 的准确率,比 ViT-H/14 仅低 0.3%,但运行速度是其 2.2 倍。

此处评论已关闭